How Nvidia's $20 billion Groq 3 LPU deal reshapes the Nvidia Vera Rubin Platform — Samsung 4nm process serves as bedrock for SRAM-based AI accelerator chip
⚡ Quick Hits
- Nvidia is investing $20 billion to integrate Groq's SRAM-based LPUs into its next-generation Vera Rubin Platform.
- The Groq 3 accelerators are manufactured using Samsung's highly efficient 4nm process node.
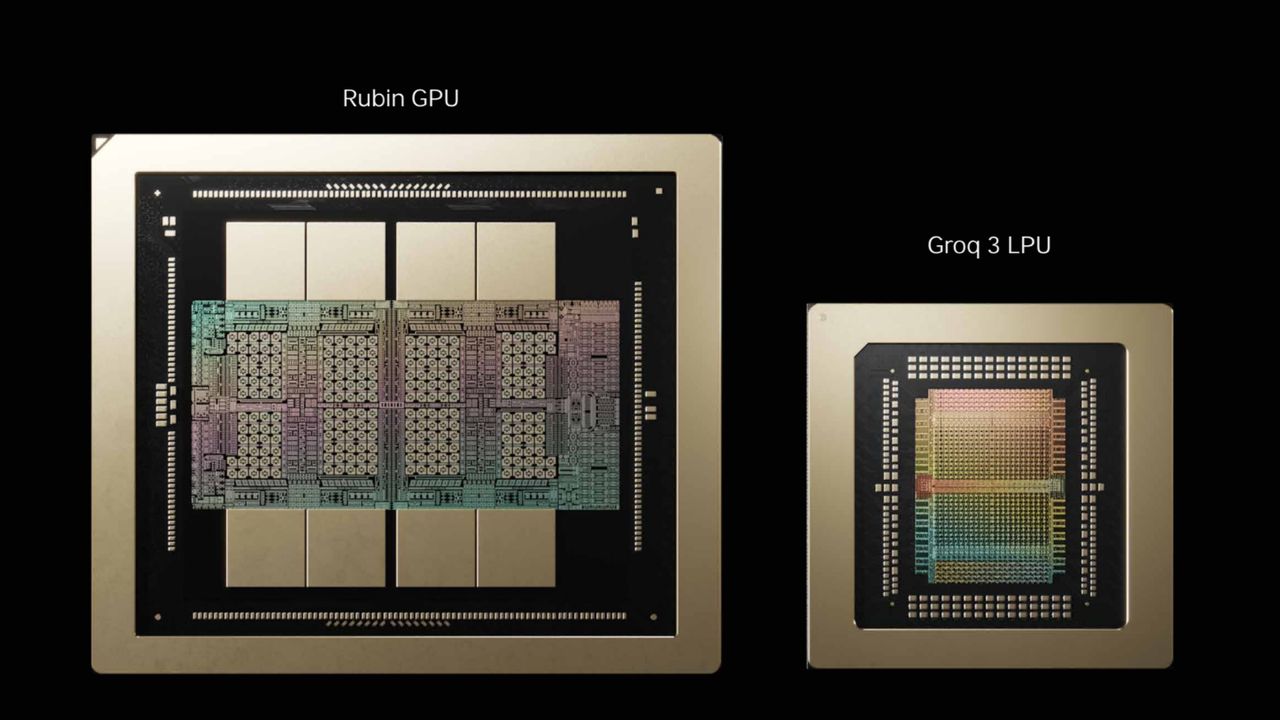
- By placing the Rubin GPU next to the Groq LPU, Nvidia aims to shatter traditional memory bottlenecks in AI processing.
Greetings, tech disciples! The Tech Monk here, bringing you the latest revelation from the silicon heavens. If you thought the AI hardware wars couldn't get any hotter, Nvidia just dropped a $20 billion bombshell that is going to fundamentally rewrite the architectural rulebook.
Nvidia has secured a massive $20 billion deal to integrate the Groq 3 LPU (Language Processing Unit) into its highly anticipated Nvidia Vera Rubin Platform. Instead of relying solely on traditional HBM (High Bandwidth Memory), this bold partnership leverages Groq's cutting-edge, SRAM-based AI accelerator chips to drastically reduce latency and power through AI inference tasks at unprecedented speeds.
Interestingly, Samsung is the silent bedrock of this revolution. The Groq 3 LPUs will be manufactured on Samsung's 4nm process, proving that the Korean tech giant remains a critical pillar in the global AI supply chain.
So, what does this mean for the future of AI hardware? By placing the next-generation Rubin GPU directly next to the Groq LPU, Nvidia is creating a dual-engine powerhouse. The GPU will continue to handle the heavy lifting of raw training throughput, while the SRAM-loaded Groq LPU will deliver blistering, bottleneck-free inference. It's a match made in silicon nirvana, and it sets a staggering new benchmark for the rest of the industry to chase.
Stay tuned, and keep your systems cool—the Vera Rubin era is going to be incredibly fast.


